Tech News
Why is streaming data and real-time AI critical in telecom?
In an era where connectivity is the lifeblood of our digital world, the telecom industry stands at the forefront of technological evolution. As the…
Read moreThe adage "Data is king" holds in data engineering more than ever. Data engineers are tasked with building robust systems that process vast amounts of data. However, the actual value of these systems lies not in their sophistication but in the quality of the data they handle. Poor data quality can lead to misleading insights, potentially derailing entire businesses. This is especially critical in streaming data environments where real-time processing and immediate decision-making are paramount.
In this blog post, we'll explore the intricacies of data quality in streaming systems, focusing on Apache Flink—a powerful framework for stream processing. We'll discuss critical aspects of data quality, including completeness, uniqueness, timeliness, validity, accuracy, and consistency, and how to implement these within a streaming architecture. This tutorial provides valuable insights into maintaining high data quality in your streaming systems.
Data engineers are responsible for building scalable, robust, and reliable systems that process vast amounts of data. While technical aspects and system performance are undeniably crucial, the actual value lies in the data. Incomplete or incorrect data can undermine sophisticated systems, leading to misleading reports and poor decision-making. Even advanced generative AI models, when fed with low-quality data, become machine learning algorithms incapable of delivering reliable insights. Put, conclusions drawn from poor data can lead to disastrous outcomes.
Data quality is a broad and multifaceted discipline that can be broken down into six key aspects:
Understanding data quality requires a holistic approach, where quality rules are implemented from the beginning of a system or even during its design. For instance, consider the process of collecting a user's email address. Here's how each aspect of data quality would apply:
This example illustrates that data quality is deeply intertwined with human processes and system design. It cannot be treated as an afterthought but must be integrated into every data lifecycle stage. While it's impossible to address every aspect of data quality in a single discussion, this article will explicitly use the Apache Flink framework to focus on some of the most common challenges in data engineering related to streaming.
By understanding and implementing data quality practices, data engineers can ensure that their systems perform well and produce reliable, high-quality data that drives informed decision-making.
There are two primary approaches to ensuring data quality: proactive and reactive. The proactive approach aims to prevent data quality issues by validating input data, adhering to business rules, and enforcing data schemas that ensure correctness, consistency, completeness, and other quality aspects. In contrast, the reactive approach focuses on monitoring data quality after processing, identifying issues, and correcting any errors that may have occurred. Each methodology has strengths and weaknesses and can be combined to create a more comprehensive, integrated system. In extreme cases, the proactive approach may halt data processing to maintain quality, while the reactive approach might allow poor-quality data to slip through.
The pattern of prevent (proactive), detect, and correct (reactive) establishes feedback loops, enabling the development of adaptive proactive strategies that evolve. This approach also naturally fits within a continuous integration methodology, allowing for better allocation of resources (time, budget) to areas where they are most needed.
Now, let’s delve into streaming and explore how to leverage both approaches effectively.
Data validity encompasses the format, type, range, domain, and adherence to business rules. Implementing validity rules is often straightforward, as they typically apply to individual records. Using a proactive approach, invalid records can be corrected or routed to a dead-letter queue for further analysis.
However, defining data quality rules can only be challenging with sufficient business and domain knowledge. One approach is to analyze representative data samples to extract information about data types, ranges, structures, constraints, and relationships with other datasets. This process, known as data profiling, can also monitor data and detect anomalies.
AWS provides a perfect data profiling tool for Spark as part of AWS Glue Catalog Data Quality. This tool summarizes the data, integrates data quality rules into ETL jobs, and detects anomalies. All are built around the Deequ library, which can be used in any Spark job. Unfortunately, I have not found a comparable alternative for Flink, but many of these features can be implemented quickly.
Let’s assume we have a Flink dynamic table with a text value column containing decimal numbers. Profiling this column can help us determine the appropriate scale and precision and set up necessary constraints. It’s crucial to analyze factors such as the number of null or empty string values, non-numeric counts, minimum and maximum values, a scale histogram, and, optionally, mean and standard deviation.
This analysis can be performed using predefined SQL aggregation functions like COUNT, MIN, and MAX, grouped within a window. However, I’ve found it more efficient in terms of development time to create reusable user-defined functions (UDFs) that calculate multiple metrics simultaneously. Ultimately, the SQL query might look something like this:
WITH profiled_data AS (
SELECT
PROFILE_RAW_DECIMAL(raw_decimal) AS metrics
FROM TABLE (
CUMULATE(TABLE raw_data, DESCRIPTOR(event_time), INTERVAL '30' SECONDS, INTERVAL '2' HOURS)
)
GROUP BY window_start, window_end
)
SELECT
pd.metrics.*
FROM
profiled_data pdThe PROFILE_RAW_DECIMAL function is defined as:
@DataTypeHint(value = """
ROW<count BIGINT,
null_count BIGINT,
not_null_count BIGINT,
nan BIGINT,
mean DOUBLE,
min DOUBLE,
max DOUBLE,
std_dev DOUBLE,
max_precision INT,
scale_hist MAP<INT, BIGINT>
\>""")
public class RawDecimalProfileFunction extends AggregateFunction<Row, RawDecimalAggregator> {
...The output will offer valuable insights into the data, which can be used to define the appropriate data types and constraints when combined with business knowledge. Need monitoring, alerting, or anomaly detection? Stream the data to a time-series database and visualize it for real-time analysis!
A data contract is an agreement between data producers and consumers that defines the data's format, type, business rules, ownership, and more. While it's a core concept in data governance, certain aspects should be incorporated into any streaming job. At a minimum, this involves implementing a Schema Registry, which defines the schema of messages and the rules for their evolution. The Confluent Platform builds on this by adding governance features (part of Confluent Data Governance), allowing additional metadata such as owner, description, tags, and data quality rules to be stored alongside the schema. Moreover, data quality rules can be enforced during message publication (with the appropriate client library), and messages failing validation are automatically routed to a Dead Letter Queue (DLQ).
Timeliness in data quality refers to aspects like data availability, latency, freshness, refresh frequency, and synchronization. The goal of streaming is to process data in real or near-real time. Apache Flink can help achieve this only if a job is implemented in a performant, scalable, stable, and robust manner. Job optimization is a complex topic; you can find some tips and tricks in our previous blog posts.
Flink comes with built-in metrics that can be exposed in multiple formats, enabling you to monitor almost every technical aspect of a job, from uptime and the number of restarts to record and byte rates, CPU and memory usage, backpressure, and more. Monitoring job performance is crucial for detecting issues like data skew or downtime.
Monitoring latency, however, is a challenging task. Flink allows for measuring state access and approximated end-to-end latency. It’s important to note that end-to-end latency monitoring evaluates the entire job topology, including each operator, sink, and subtask, and provides latency histogram metrics for each component. This can significantly impact performance, so it is turned off by default and should be used only for debugging.
Alternatively, you can build a custom application that periodically sends test data and monitors its arrival at the sink operator. This approach treats the processing framework as a black box and can naturally evolve into a method for executing smoke tests in the environment. The application should be lightweight, as it only measures latency for sample scenarios.
Data latency should remain consistent, regardless of job pressure. Job parallelism and assigned resources should be scaled up during peak data periods and down when the load is low, minimizing infrastructure costs. Starting from version 1.17, Flink provides:
Based on this analysis, it can automatically adjust parallelism and required resources. Version 1.18 introduced a significant improvement by allowing in-place scaling of vertices without requiring a complete job upgrade cycle, thereby eliminating (sometimes substantial) downtime caused by scaling.
The last aspect of timeliness is synchronization. Flink allows you to define time in your pipeline based on ingestion, processing, or event time. Watermarks are calculated from this time, which helps track progress and synchronize streams using window or join operators. However, it's important to remember that the time concept requires events to be at least approximately monotonicity, which is only sometimes guaranteed. Out-of-order records may become late events, which are dropped by default. It's always a good practice to route these via a side output to a DLQ for later analysis. Another potential synchronization issue is idle sources, which may halt job progress or introduce additional latency.
Data completeness refers to both attribute and record completeness. Attribute completeness ensures that each data field contains the expected values, while record completeness verifies that the dataset includes all necessary records. Completeness can be measured by:
Cross-validation is only possible in specific scenarios, such as application migration to a new tech stack or processing Change Data Capture (CDC) events with source RDB as a reference point, and it can be challenging to implement in streaming environments.
Flink makes it easy to define metrics, which can be implemented in any function in both Table and DataStream API. To count null values, I created a User Defined Function that increments a null counter and returns the unmodified input value. This function is designed to work independently of the input type and is compatible with datastreams (not changelogs).
public class NullCheckFunction extends ScalarFunction {
private transient MetricGroup metricGroup;
private transient Map<String, Counter> nullCounters;
public <T> T eval(T value, String metricName) {
if (value == null) {
getCounter(metricName).inc();
}
return value;
}
@Override
public void open(FunctionContext context) throws Exception {
metricGroup = context.getMetricGroup();
}
private Counter createCounter(String metricName) {
return metricGroup.counter(metricName);
}
private Counter getCounter(String metricName) {
if (nullCounters == null) {
nullCounters = new HashMap<>();
}
var counter = nullCounters.get(metricName);
if (counter == null) {
counter = createCounter(metricName);
nullCounters.put(metricName, counter);
}
return counter;
}
public TypeInference getTypeInference(DataTypeFactory typeFactory) {
return TypeInference.newBuilder().outputTypeStrategy(new ForwardArgumentTypeStrategy(1)).build();
}
@RequiredArgsConstructor
private class ForwardArgumentTypeStrategy implements TypeStrategy {
private final int argIdx;
@Override
public Optional<DataType> inferType(CallContext callContext) {
return Optional.of(callContext.getArgumentDataTypes().get(argIdx));
}
}
}
\
...
tableEnv.createTemporaryFunction("NULL_CHECK", NullCheckFunction.class);This is just one example of how to create metrics dynamically, showcasing a powerful feature that allows you to monitor the quality of your data.
Data set completeness is more challenging. Let's assume we have two dynamic tables that need to be joined. The left table contains foreign keys referencing the right table. Streams can be joined with time-based synchronization, such as a temporal join, or without synchronization, relying on the changelog concept and based on the operator's state, like a regular join.
A temporal join synchronizes streams based on a defined time, pausing the processing of the left stream until the right stream's watermark reaches the expected level. This algorithm requires idle source detection to prevent the processing from stopping when no new records arrive in the right stream. An idle timeout marks a source as idle, allowing data processing to continue. However, the challenge is determining whether the absence of new data is problematic.
We can monitor completeness by using an outer join and a null count metric for the right-side join key. Invalid records may be skipped or routed to a DLQ, depending on the requirements. However, this quality rule will only detect updates from a changelog.
A regular join doesn't synchronize data streams. It retains the latest records from both streams in the state and releases matched data. In the case of an outer join, the operator returns the input record immediately, regardless of whether it matches any record from the other stream. This may lead to temporary incompleteness due to the need for synchronization. Completeness should be checked with some delay by the timeliness quality rule.
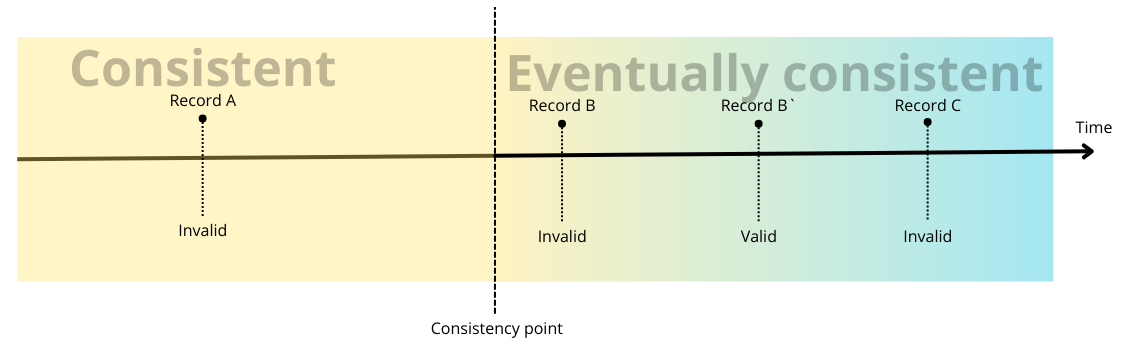
The picture below illustrates the temporary invalid state on the right side of the consistency point. Initially invalid, Record B becomes valid after an update (B'). In contrast, Record A, temporarily valid at the beginning, becomes invalid after reaching the consistency point due to the absence of updates within the expected time. Record C remains temporarily invalid throughout.
Delayed validation can be easily implemented in Flink using the timer service. Below is an example of such a function.
@RequiredArgsConstructor
public class EventualConsistencyRuleFunction extends KeyedProcessFunction<String, Row, Row> {
private final String\[] notNullColumns;
private final long consistencyDuration;
private final String metricName;
private ValueState<Long> consistencyPointState;
private Counter invalidCounter;
@Override
public void processElement(Row row, Context ctx, Collector<Row> out)
throws Exception {
var rowInvalid = false;
for (var column : notNullColumns) {
if (row.getField(column) == null) {
rowInvalid = true;
break;
}
}
if (rowInvalid) {
row = copyRowWithInvalidColumn(row, true);
if (consistencyPointState.value() == null) {
var consistencyPoint = ctx.timerService().currentProcessingTime() + consistencyDuration;
ctx.timerService().registerProcessingTimeTimer(consistencyPoint);
consistencyPointState.update(consistencyPoint);
}
} else {
row = copyRowWithInvalidColumn(row, null);
clearTimer(ctx);
}
out.collect(row);
}
private void clearTimer(Context ctx) throws Exception {
var consistencyPoint = consistencyPointState.value();
if (consistencyPoint != null) {
ctx.timerService().deleteProcessingTimeTimer(consistencyPoint);
consistencyPointState.clear();
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Row> out)
throws Exception {
invalidCounter.inc();
}
}After the regular join, the function should be executed, and the primary key columns from the right-side table should be checked. Each incomplete record is marked invalid, but the metric counter is only incremented after reaching the consistency point, provided no valid record has appeared beforehand.
It's worth noting that Flink allows you to convert between the Table API (SQL) and the DataStream API and vice versa. This flexibility enables you to write SQL queries and define data quality metrics in a more predictive and seamless manner.
Data streams are inherently infinite. While this is not strictly true technically, the volume of data can be massive. Apache Flink supports deduplicating records using predefined functions, but tracking unique values requires maintaining state. Over time, this state can grow significantly, potentially limiting job throughput or causing processing failures. While Flink's scalability allows you to address these limits by providing additional resources, this may only offer a temporary solution.
Instead of performing global deduplication, you can opt for local deduplication, which often mitigates many of these issues. For example, sessions are relatively short-lived in clickstream data, so deduplicating events within a few minutes is usually sufficient.
There are two main methods to achieve this:
Deduplication in Flink is a prime example of a proactive approach where data streams are corrected in real-time.
Data accuracy refers to the degree to which data accurately represents real-world entities or events. The key aspects of accuracy are correctness and precision. The Flink framework offers several mechanisms to ensure data accuracy in your streaming jobs.
Flink offers various connectors that can act as lookup tables, allowing you to fetch additional information and validate processed data against a reference. If I/O operations become a bottleneck and the client library supports asynchronous operations, you can invoke these as Flink async functions. This approach prevents wasting CPU time while waiting for responses, thereby increasing throughput. Additionally, Flink can automatically retry operations, providing unordered or ordered results with an exactly-once fault tolerance guarantee. However, the capacity parameter (maximum number of requests in progress) should be set carefully. Setting too high can overwhelm the server with requests and prevent backpressure creation in the Flink job.
That's the theory. In practice, executing cross-referencing is challenging. An external dependency introduces another potential point of failure and can limit the scalability of your job. It's important to note that some databases have limits on concurrent request processing. Streaming jobs with high parallelism and asynchronous I/O functions can easily hit those limits, resulting in multiple retries, performance degradation, or even job failures. Moreover, limited database availability can also affect other dependent components. Therefore, use proactive cross-referencing wisely, especially for low-throughput pipelines when low latency and stability are not crucial.
An alternative to proactive cross-referencing is reactive validation on the result dataset. This approach is feasible when the job's sink is a database, data lake, or warehouse. Although seemingly straightforward, this task can take time to implement. First, the job's output is eventually consistent with the reference data. Second, you must consider the technical limitations of the "source of truth" system.
In some cases, retrieving reference data requires expensive or slow queries, making it impossible to validate the entire output. Using representative data samples can be a practical trade-off. Flink SQL in batch mode can be beneficial for this purpose, as batch validation is more accessible to implement, offers a broader range of optimization techniques, and helps unify data types for comparison.
Note that an excellent report should detect issues and make it easy to identify and resolve their source. Flink allows you to define multiple sinks in a job, enabling you to write invalid records to one sink while simultaneously generating metrics or a report summary.
Flink supports event time processing, crucial for accurate time-based calculations and aggregations. By using event time rather than processing time, you ensure that your data is processed correctly, even if events arrive out of order.
Flink offers fault tolerance guarantees, including "at most once," "at least once," and "exactly once," depending on the source, sink, and configuration used. Choosing the appropriate guarantee level is essential to ensure that each event is processed correctly and to avoid duplicates in sink components.
Writing unit tests for Flink is straightforward, thanks to the test harness, which allows you to control various aspects of the operator, such as time, state, and watermarks. Additionally, you can perform end-to-end tests with sample data by simply replacing the source and sink functions.
It's crucial to build a comprehensive unit test suite for custom functions or UDFs and extend it whenever a new issue is detected. This approach helps you better understand use cases, corner cases, and the data domain while also helping to avoid regressions. Plus, it serves as excellent in-code documentation!
Flink's flexible mechanism for defining data quality metrics enables the creation of complex monitoring systems with anomaly detection capabilities. This allows you to track data accuracy and identify potential issues. In some cases, cross-reference validation within your pipeline can be challenging, but extracting key metrics from both systems is still possible. Monitoring discrepancies in these metrics can offer valuable insights into the data, providing a solid foundation for reactive data quality monitoring.
Ensuring data quality in streaming is a complex task that must be addressed. The Flink framework provides a range of mechanisms that can effectively address almost every aspect of data quality. However, working with streaming data is more challenging than batch processing due to the additional time dimension. This blog helps to systematize the issues related to data quality and provides valuable insights for solving these issues.
Are you interested in diving even deeper into the world of data quality? Join the waiting list for our upcoming eBook, "Data Quality No-Code Automation with AWS Glue DataBrew: A Proof of Concept," where we explore comprehensive strategies, tools, and best practices for ensuring top-tier data quality in any environment. Sign up now to be the first to receive exclusive insights and expert tips to enhance your data quality management!
In an era where connectivity is the lifeblood of our digital world, the telecom industry stands at the forefront of technological evolution. As the…
Read moreTrend 4. Larger clouds over the Big Data landscape A decade ago, only a few companies ran their Big Data infrastructure and pipelines in the public…
Read moreWhen you search thought the net looking for methods of running Apache Spark on AWS infrastructure you are most likely to be redirected to the…
Read moreWe are excited to announce that we recently hit the 1,000+ followers on our profile on Linkedin. We would like to send a special THANK YOU :) to…
Read moreDiscovering anomalies with remarkable accuracy, our deployed model successfully identified 90% true anomalies within a 2-months evaluation period…
Read moreData space has been changing rapidly in recent years, and data streaming plays a vital role. In this blog post, we will explore the concepts and…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?