Tech News
Panem et circenses — how does the Netflix’s recommendation system work.
Panem et circenses can be literally translated to “bread and circuses”. This phrase, first said by Juvenal, a once well-known Roman poet is simple but…
Read moreData processing in real-time has become crucial for businesses, and Apache Flink, with its powerful stream processing capabilities, is at the forefront. However, one challenge that persists is data skew, especially when dealing with large-scale data. In this blog, I will explore effective strategies to mitigate data skew in Flink SQL, ensuring efficient and balanced processing.
Flink SQL is the framework that enables the rapid and relatively easy development of batch and streaming transformations. In my opinion, it should be referred to as "Flink + SQL" (with a plus sign between them) because being familiar with SQL isn't sufficient. While SQL proficiency eliminates the necessity to learn programming languages such as Java, Scala or Python, a solid knowledge of the basics of Flink remains essential for constructing efficient streaming pipelines.
To begin with, it's beneficial to understand the concept of dynamic tables and the distinction between changelog and append-only streams. For data alignment, defining watermarks and constructing aggregations based on window functions may be necessary.
Table joins in Flink are similar to those in relational databases. Depending on the business requirements, you might require regular, temporal, or lookup joins, each functioning differently and potentially producing distinct outcomes.
Despite offering multiple join types, Flink has only two join strategies in streaming mode. The first is the lookup join, a unique strategy for lookup tables or views. It is executed in place (without data shuffling), but requires external storage for fetching data. It proves advantageous for joining with slowly changing dimension tables, such as dictionaries, or in scenarios where storing data in Flink state is undesirable (e.g. a huge table), and data alignment isn't a concern.
The primary strategy resembles the shuffle hash join. In this method, rows from the joined tables are distributed to subtasks based on hashes calculated from join key values. However, the performance of this join may be affected by a few very common values, such as NULLs.
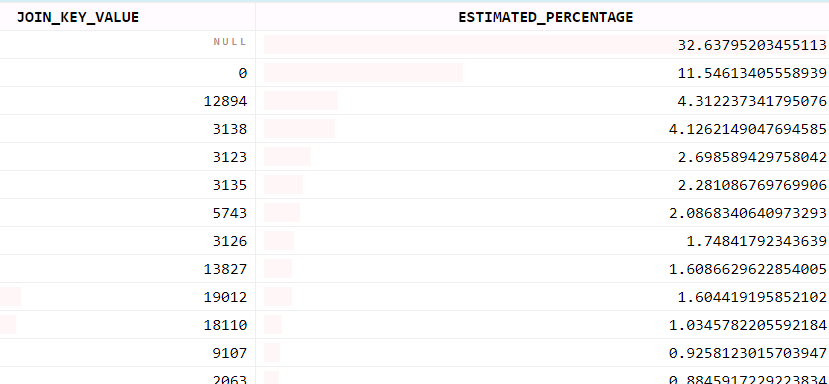
Consider a scenario where we need to perform a left join between the large table TABLE_A (with 140 million rows and growing) and a small dictionary TABLE_B. Both are dynamic and based on Kafka topics. The distribution of join key values is presented in the image below.
Data skew is almost certain in this scenario, as the top 5 values account for over 50% of the data. Moreover, the most common NULL value is present in 32.6% of the data. JOIN_KEY_VALUE is a non-negative integer value.
In Spark during batch processing, there are techniques such as salting join keys, and optimized join strategies like broadcast hash join or storage partitioned join (introduced in Spark 3.3), which can address data skew issues. Unfortunately, Flink doesn’t support them in streaming mode, and well-known Spark’s techniques can not be adopted directly.
Flink distributes rows based on the join key value. Null ensures that rows won't be joined and can be passed through the join operator. However, Flink SQL routes all NULL values to the same subtask, requiring intervention to ensure equal distribution.
The solution involves utilizing data constraints and substituting NULL values in the join statement with any value out of the range. While it could be a random value, I recommend using a deterministic one (deterministic value = deterministic pipeline). Since Flink won't find any corresponding right-side value, it will pass the left table row unjoined.
To achieve this, I decided to calculate a negative integer using the MD5 hash function based on the primary key from TABLE_A. The resulting value will consistently fall within the range of -1999 to -1000, regardless of the PK type or value range.
FROM
TABLE_A a
LEFT JOIN
TABLE_B a
ON
COALESCE(a.JOIN_KEY_VALUE, CAST(SUBSTRING(HEX(MD5(CAST(a.ID AS STRING))) FROM 0 FOR 3) AS INT) - 1999) = b.IDThis workaround isn't limited to regular joins. It applies to temporal joins as well. In the case of temporal joins, you'll need to move the COALESCE expression to the computed column within TABLE_A and then use it in the join statement. While this approach functions as a workaround, it's crucial to note that Flink will fail if you use computed expressions directly within a temporal join statement.
The distribution of rows with a NULL join key depends on TABLE_A’s primary key, resulting in a well-balanced distribution. This effectively resolves the data skew problem.
This concept combines the salting key technique with a broadcast join. The salt, referred to in this article as BROADCAST_ID, improves data distribution, while the pseudo-broadcast enables the processing of rows by multiple Flink subtasks.
The pattern of a pseudo-broadcast join is as follows:
CREATE TABLE_B (
...,
BROADCAST_ARRAY AS ARRAY[0,1,2,3,4,5,6,7] --step 1
) WITH (
...
);
CREATE VIEW TABLE_B_FLATTEN AS
SELECT
t.*,
b.BROADCAST_ID
FROM
TABLE_B t
CROSS JOIN --step 2
UNNEST(t.BROADCAST_ARRAY) AS b (BROADCAST_ID)
;
CREATE TABLE TABLE_A (
...,
BROADCAST_ID AS CAST(SUBSTRING(HEX(MD5(CAST(ID AS STRING))) FROM 0 FOR 4) AS INT) % 8 --step 3
) WITH (
...
);
SELECT
...
FROM
TABLE_A a
JOIN
TABLE_B_FLATTEN b
ON
a.JOIN_KEY_VALUE = b.ID
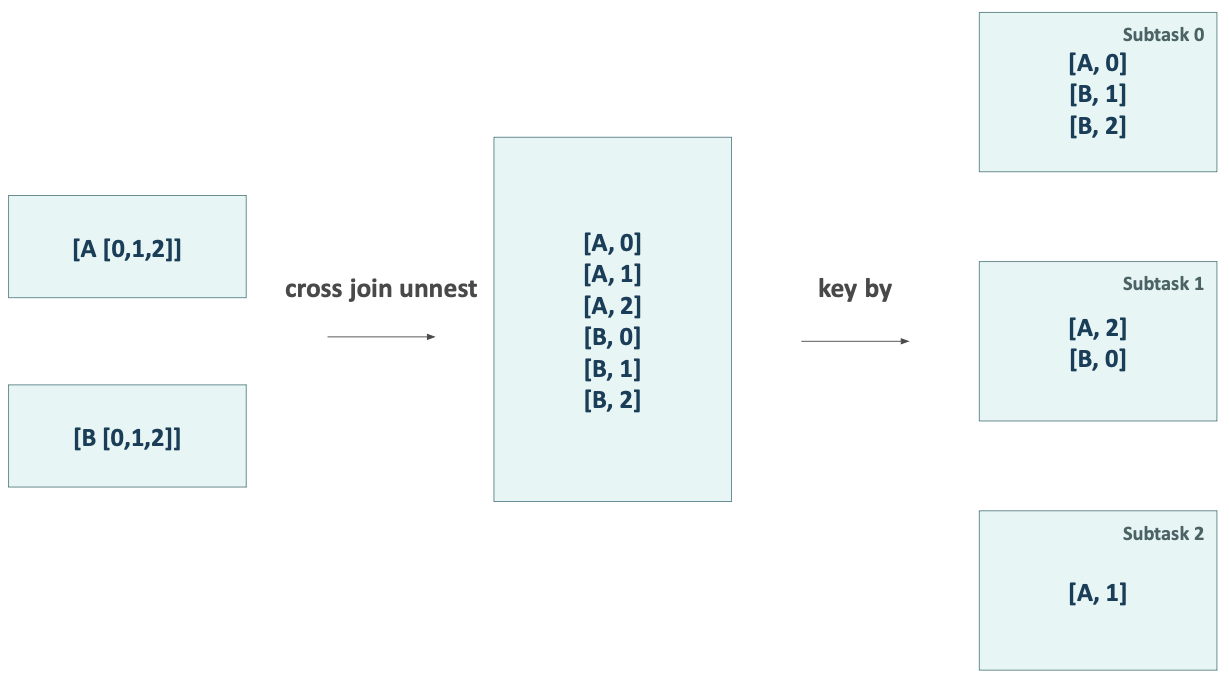
AND a.BROADCAST_ID = b.BROADCAST_ID --step 4How does it work? The right table is flattened using a cross-join unnest operator (since pure cross-join isn't supported in Flink streaming). This operation generates duplicates with distinct BROADCAST_IDs. Duplicated rows will be distributed across multiple subtasks, but we cannot control how Flink will distribute our data.
In the provided illustration, the row with JOIN_KEY_VALUE (B) isn't optimally distributed. For instance, Subtask 0 retains instances (B, 1) and (B, 2), while Subtask 2 lacks any (B) row. Additionally, in our scenario, the join on value (A) can be managed by any subtask, while (B) is processed by two out of three subtasks.
The final step involves calculating BROADCAST_ID on the left table. It's crucial to "rotate" that value, utilizing as many subtasks as possible. I decided to use the MD5 hash function from the left table's primary key (similar to NULLs distribution). Since my left table is constructed from CDC events, PK values shouldn't be frequently repeated.
The BROADCAST_ARRAY is utilized to replicate rows, with its size determined empirically. In an ideal scenario, its size should match the job's parallelism. However, due to lack of control over data distribution, it's sensible to use a higher value to facilitate processing on any of the subtasks. On the other hand, excessive duplicates can consume memory and impact operator state size, as well as subsequent checkpointing. Hence, I empirically increased the size of the BROADCAST_ARRAY to mitigate data skew. Its optimal size is closely related to your data and the job's parallelism.
The data skew issue is resolved. Flink enforced multiple subtasks for processing left joins with the same join key value. While this doesn't guarantee perfectly balanced traffic across subtasks, it significantly reduces the impact of data skew within the left join operator. The crucial parameters here are the range of BROADCAST_ID on the right table and the rotation of BROADCAST_ID on the left table.
However, it's important to note that duplicating the right table adds memory overhead. Each row will be kept in state.
This technique serves as a workaround for Flink's limitations. Additionally, Flink still needs to serialize and deserialize rows from the left table (it isn’t a broadcast join, which can be processed in place), and the scalability isn't automatic. Scaling up your job may require increasing the BROADCAST_ARRAY range. After that change, you have to start a new job. Upgrading the existing state won’t be possible.
Addressing data skew in Flink SQL is crucial for maintaining efficient and balanced data processing. By implementing strategies like handling NULL values deterministically and using pseudo-broadcast joins, data engineers can significantly mitigate skew and improve performance. As Flink continues to evolve, these techniques provide a robust foundation for tackling one of the most persistent challenges in stream processing.
Mitigating data skew in Flink SQL involves understanding the underlying concepts, implementing effective join strategies, and evaluating the results. By applying best practices, businesses can ensure efficient and balanced processing, paving the way for robust real-time data analytics. Are you looking to address data skew challenges in your Flink SQL projects? Schedule a free consultation with our experts to optimize your data processing pipelines and achieve seamless performance. Also, sgn up for our newsletter to stay updated on the latest strategies and insights in data engineering.
Panem et circenses can be literally translated to “bread and circuses”. This phrase, first said by Juvenal, a once well-known Roman poet is simple but…
Read moreBusinesses across industries are using advanced data analytics and machine learning to revolutionize how they operate. From detecting anomalies to…
Read morePlanning any journey requires some prerequisites. Before you decide on a route and start packing your clothes, you need to know where you are and what…
Read moreYou have just installed your first Kubernetes cluster and installed Istio to get the full advantage of Service Mesh. Thanks to really awesome…
Read moreThe need for a unified format for geospatial data In recent years, a lot of geospatial frameworks have been created to process and analyze big…
Read moreStarting a company from scratch as first-time founders can be very challenging, but being active community members can make all the difference…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?