

Why do Big Data projects fail? Part I. The Business Perspective.
In a recent post on out Big Data blog, "Big Data for E-commerce", I wrote about how Big Data solutions are becoming indispensable in modern business…
Read moreWelcome back to the dbt Semantic Layer series! This article is a continuation of our previous article titled “dbt Semantic Layer - what is and how to use”. In case you missed it and would like to read - please follow this link.
We strongly encourage you to first read the previous article, since it describes what dbt is, what a dbt Semantic Layer is and how to use it. This article will be a continuation of the story and we will show you step by step what needs to be done in order to implement the dbt Semantic Layer.
To use the dbt Semantic Layer, you need to create a dbt project and configure a service account. This setup requires a paid Team or Enterprise plan. For detailed instructions on projects, licenses and service tokens, refer to the dbt documentation.
If you don’t have a dbt project yet then you can use the dbt guideline to set up a sample project using one of the available data sources. Here you can find helpful material: dbt Quickstarts Guides. When you are all set up, then please follow the instructions below to implement the Semantic Layer.
Within the ‘models’ folder, create a new sub-folder ‘semantic_models’ and then create the YAML file containing the definition of specific Semantic Layer. You can have multiple SL files there, but the names should be unique e.g. ‘SL_orders.yml’. Keep in mind that storing SL files outside of the ‘models’ folder will result in a run error.
The structure of the semantic layer is as follows:
semantic_models:
- name: the_name_of_your_semantic_model ## Required; name of each model needs to be unique
description: same as always ## Optional; write here the description of what this SL model and what is its purpose
model: ref('some_model') ## Required; here put name of the model that you want to use as a foundation of any future calculations e.g. some fact table
defaults: ## Required
agg_time_dimension: dimension_name ## Required if the model contains measures; specify which column will be used for calucations in time
entities: ## Required
- ## define here columns used for joining
- ## define here the primary entity, usualy the main fact table
measures: ## Optional
- ## define here the columns to be used for calculations and basic logic
dimensions: ## Required
- ## specify here which tables you will be using as Dimensions to caluclate the measures
primary_entity: >-
if the semantic model has no primary entity, then this property is required. ##Optional if a primary entity exists, otherwise Required
metrics: ## Place here or in separate YAML file
- ## define here advanced logic of your metrics; see Step 2 for more detailsYou need to adjust the SL definition to your specific business needs in order to benefit from it. Here you can find the detailed information from dbt Labs on how to define semantic models - dbt documentation.
See the sample SL YAML configuration below:
semantic_models:
- name: customers
defaults:
agg_time_dimension: most_recent_order_date
description: |
semantic model for dim_customers
model: ref('fact_customer_orders') ## Model combining orders and customer data
entities:
- name: customer
expr: customer_id
type: primary
dimensions:
- name: customer_name
type: categorical
expr: first_name
- name: first_order_date
type: time
type_params:
time_granularity: day
- name: most_recent_order_date
type: time
type_params:
time_granularity: day
measures:
- name: count_lifetime_orders
description: Total count of orders per customer.
agg: sum
expr: number_of_orders
- name: lifetime_spend
agg: sum
expr: lifetime_value
description: Gross customer lifetime spend inclusive of taxes.
- name: customers
expr: customer_id
agg: count_distinct
metrics:
- name: "customers_with_orders"
label: "customers_with_orders"
description: "Unique count of customers placing orders"
type: simple
type_params:
measure: customersThe heart of the SL model are metrics - here you define the complex business logic using the advanced options. They can be created both in the SL model YAML file and in a separate YAML file called ‘SLModelName_metrics.yaml’ (e.g. customer_orders_metrics.yaml) within the models/semantic_models sub-folder. Both options will work and it is up to the developer which one is chosen. However, keeping metrics in a separate file provides a better look at the definition thanks to less information within the same file.
To create a metric you need to define at least the name and type. The yype defines how the calculations will be performed and what measures should be included in the logic. Each metric is calculated on top of the measure, which you defined in the semantic_model.yaml file.
There are two groups of metrics: simple and complex. The first ones usually use one measure and just present it to the user. The second ones take one or many measures and add some advanced calculations on top of them e.g. conversion, cumulation, ration, filtering.
The structure of metrics definitions is as follows:
metrics:
- name: metric_name ## Required
description: description ## Optional
type: the type of the metric ## Required
type_params: ## Required
- ## specific properties for the metric type and measures which you want to choose in calculations
config: ## Optional
meta:
my_meta_config: 'config' ## Optional
label: The display name for your metric. This value will be shown in downstream tools. ## Required
filter: | ## Optional
{{ Dimension('entity__name') }} > 0 and {{ Dimension(' entity__another_name') }} is not
null and {{ Metric('metric_name', group_by=['entity_name']) }} > 5Sample definition of simple revenue metric:
metrics:
\- name: revenue
description: Sum of the order total.
label: Revenue
type: simple
type_params:
measure: order_totalSample definition of complex metric using ratio logic and filtering:
metrics:
\- name: cancellation_rate
type: ratio
label: Cancellation rate
type_params:
numerator: cancellations
denominator: transaction_amount
filter: |
{{ Dimension('customer__country') }} = 'MX'
\- name: enterprise_cancellation_rate
type: ratio
type_params:
numerator:
name: cancellations
filter: {{ Dimension('company__tier') }} = 'enterprise'
denominator: transaction_amount
filter: |
{{ Dimension('customer__country') }} = 'MX'Here you can find the detailed information from dbt Labs on how to define metrics - metrics overview. Please adjust the ‘ModelName_metrics.yaml’ file to address your specific business needs.
A time spine in a Semantic Model is a crucial component that ensures consistent and accurate time-based analysis. It defines the time dimensions that can be used to calculate your metrics in a time perspective.
TimeSpine is nothing else but just a model where we define the time dimension. In order to create one please create a new model named ‘metricflow_time_spine.sql’ and use SQL to create the dimension. You can use the sample code below:
{{
config(
materialized = 'table',
)
}}
with days as (
{{
dbt.date_spine(
'day',
"to_date('01/01/2000','mm/dd/yyyy')",
"to_date('01/01/2030','mm/dd/yyyy')"
)
}}
),
final as (
select cast(date_day as date) as date_day
from days
)
select * from final
where date_day > dateadd(year, -4, current_timestamp())
and date_hour < dateadd(day, 30, current_timestamp())Here is more information on MetricFlow TimeSpine - link.
After defining the semantic model and the specific metrics tailored to your needs, it's essential to ensure everything is set up correctly. To do this, run the build command in dbt Cloud (dbt build or dbt build –full-refresh). This will compile and execute your models, allowing you to identify and fix any errors that might arise.
You have the flexibility to develop the Semantic Layer (SL) in both dbt Core and dbt Cloud. In either environment, you can validate locally (no API yet, see next steps) your SL to ensure it meets your requirements. To interact with and validate your metrics within the dbt Semantic Layer, you should use the MetricFlow commands designed specifically for this purpose. See sample commands below to test your model.
## List your metrics
dbt sl list metrics <metric_name> ## In dbt Cloud
mf list metrics <metric_name> ## In dbt Core
## List available dimensions for specific measure
dbt sl list dimensions --metrics <metric_name> ## In dbt Cloud
mf list dimensions --metrics <metric_name> ## In dbt Core
## Query the model
dbt sl query --metrics <metric_name> --group-by <dimension_name> ## In dbt Cloud
dbt sl query --saved-query <name> ## In dbt Cloud CLI
## Example of ready query
dbt sl query --metrics order_total,users_active --group-by metric_time ## In dbt Cloud
mf query --metrics order_total,users_active --group-by metric_time ## In dbt Core
## Result of query
✔ Success 🦄 - query completed after 1.24 seconds
| METRIC_TIME | ORDER_TOTAL |
|:--------------|---------------:|
| 2017-06-16 | 792.17 |
| 2017-06-17 | 458.35 |
| 2017-06-18 | 490.69 |
| 2017-06-19 | 749.09 |
| 2017-06-20 | 712.51 |
| 2017-06-21 | 541.65 |Here you can find a detailed explanation of MetricFlow logic and commands - dbt documentation.
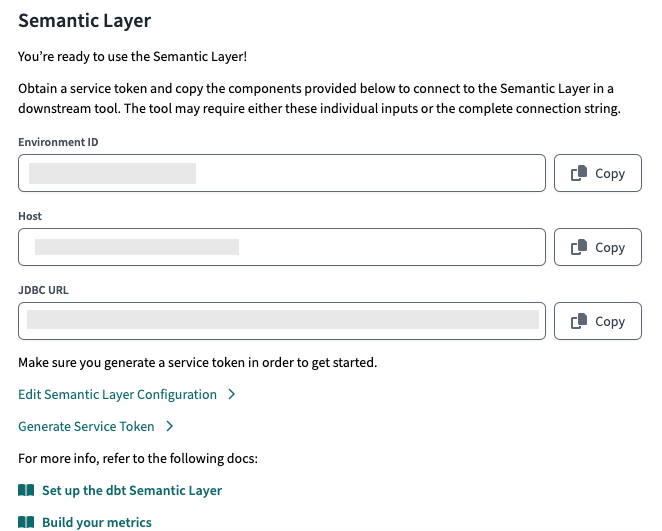
Now you have a fully functional dbt Semantic Layer, and you can use it to perform calculations. While obtaining results in your dbt Cloud or dbt Core is beneficial, this is just the beginning. The most significant value of the Semantic Layer lies in its availability via API and the ability to request custom queries through the API from dbt SL using external products. To enable this functionality, we need to set up a production deployment environment with the deployed SL logic. Next, we need to configure the Semantic Layer access point to enable communication. All of this will be covered in the following steps, so keep reading!
With the fully running job we can move to the Deploy module to create or adjust our Production environment. You need to have one PROD environment with SL logic deployed there in order to benefit from it via APIs.

In case you already have a Production environment, move on to the next step.
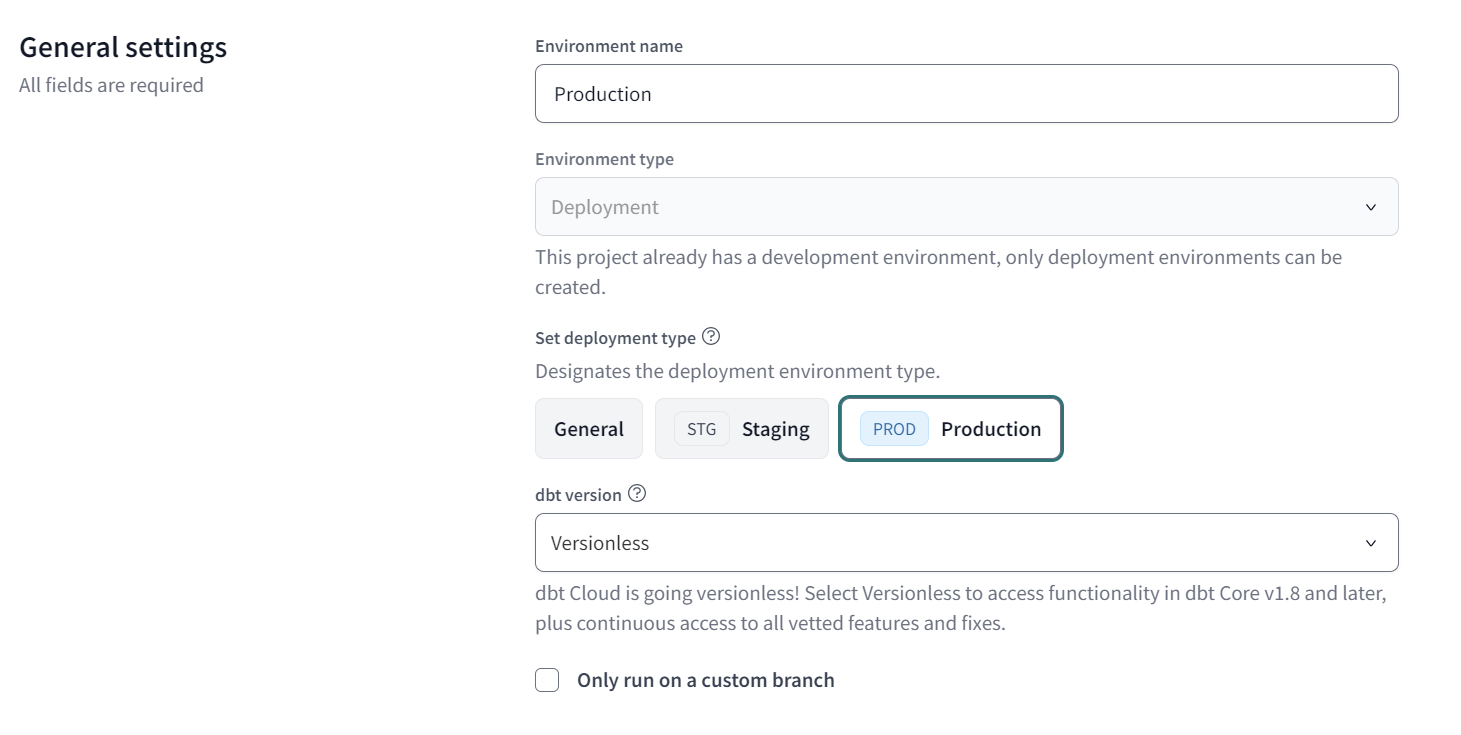
Please click the ‘Create environment’ button and wait until the configuration pop-up opens. Set the ‘Environment name’ (e.g. Production), then in ‘Set deployment type’ select Production (more information here).
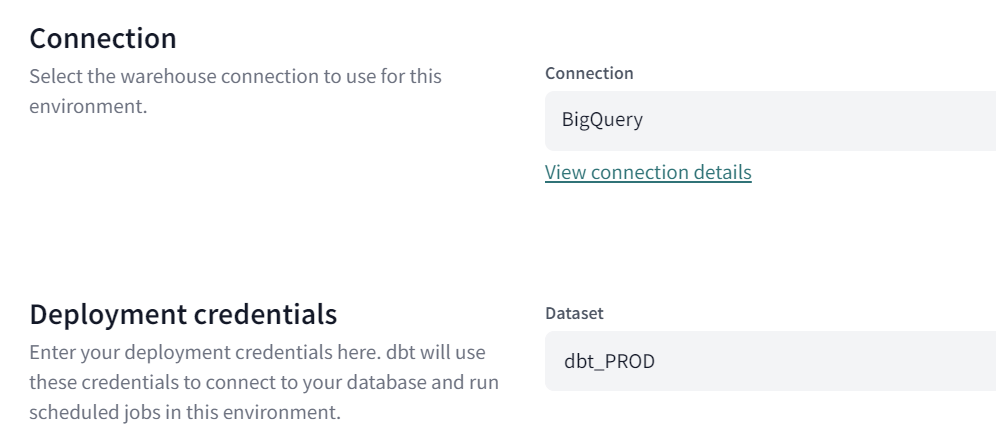
Next select the connection to be used by this environment, preferably using the same as was defined for the dbt project. The selected connection will be used to build the Production models. At the end define ‘Deployment credentials’ which will define the user name and target schema name.
See the end result of the deployment within Connection below = BigQuery, and Deployment_credentials = dbt_PROD.
After completing all of the necessary steps mentioned above, scroll up to the top and click ‘Save’.
Now we need to create a job building our project with SL configuration on Production environment in order to enable the Semantic Layer API functionality. Go to the Deploy / Jobs module to do that.
Click the ‘Create job’ button, select ‘Deploy job’. Then define the unique name, select the Production environment and click the ‘Save’ button at the top. More information on job creation can be found here.
Open the detailed page of the newly created job and click the ‘Run now’ button.
When we have SL configuration and have created a PROD environment with successfully running job there, we can now move on to the final part which is API configuration. On the dbt Cloud platform, navigate to Account Settings by clicking the settings icon in the top right hand corner, select Projects and then the name of the project you are working on.
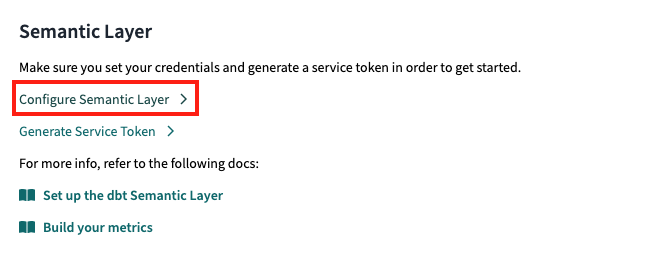
Scroll down to the ‘Semantic Layer’ section and select ‘Configure Semantic Layer’. Here you can find detailed guidelines from dbt Labs on how to set up the SL - guideline.
Remember to write down the Service Token somewhere - you will need it later on to communicate with the API.
After completing all the steps you are ready to use Semantic Layer!
The dbt Semantic Layer, if defined correctly, can provide significant advancement in a company’s data analytics. It provides a unified and consistent framework for defining business metrics and dimensions addressing a critical need for many organizations.
This guide outlines a step-by-step process for implementing the dbt Semantic Layer (SL), enabling centralized, consistent business logic across your data workflow. The process goes through semantic model definition, metrics, time dimension, deployment environment and finally API configuration.
For organizations striving to enhance their data analytics capabilities, investing in a dbt Semantic Layer is a strategic move that promises significant long-term benefits. As the data landscape continues to evolve, tools like dbt will play an increasingly vital role in shaping the future of business intelligence and analytics.
If you want to know more about dbt capabilities or you are facing other data na AI related challenges, do not hesitate to contact us or book a free consultation.
In a recent post on out Big Data blog, "Big Data for E-commerce", I wrote about how Big Data solutions are becoming indispensable in modern business…
Read moreKnowledge sharing is one of our main missions. We regularly speak at international conferences, we contribute to open-source technologies, organize…
Read moreYou could talk about what makes companies data-driven for hours. Fortunately, as a single picture is worth a thousand words, we can also use an…
Read moreFor project managers, development teams and whole organizations, making the first step into the Big Data world might be a big challenge. In most cases…
Read moreIn today's digital age, data reigns supreme as the lifeblood of organizations across industries. From enabling informed decision-making to driving…
Read moreGenerative AI and Large Language Models are taking applied machine learning by storm, and there is no sign of a weakening of this trend. While it is…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?