Data Democratization: Power Your Organizations with Data Accessibility
In today's digital age, data reigns supreme as the lifeblood of organizations across industries. From enabling informed decision-making to driving…
Read moreMLOps is an ever-evolving field, and with the selection of managed and cloud-native machine learning services expanding by the day, it can be challenging to navigate the options available. With a plethora of managed and cloud-native machine learning services available, it's crucial to choose the right platform for running machine learning pipelines and deploying trained models. However, three significant pain points persist in the MLOps landscape:
With Snowflake being a powerful data warehouse and Snowpark's ease of use, together they make a strong candidate for building complex ML pipelines. If you are not familiar with Snowpark yet, there are a lot of great articles introducing its core concepts and how you can use it for writing data science and machine learning (ML) code, e.g. here, here or here.
There are however at least a few shortcomings of the currently proposed approaches that have not yet been addressed:
ML pipelines orchestration - in the current state, two strategies can be pursued:
Unfortunately, neither of these methods seem to be free from flaws - the former requires additional scheduling components to be included in the architecture that makes it more complex and less platform-independent. The latter one is less user-friendly as it requires not only developing training code, but also defining Snowflake DAGs of tasks by means of plain SQL or Terraform programming language.
The above list of challenges clearly indicates missing the integration of the Snowflake environment with an MLOps framework, such as Kedro.
Today we are proudly announcing a solution that will fill this gap - the kedro-snowflake plugin. In the next post we will also guide you through the whole MLOps platform and ML model deployment on Snowflake. However, let's first take a look at what Kedro is and then let's build an ML pipeline in Kedro and execute it in the Snowflake environment in 3 simple steps.
Kedro is a widely-adopted, open-source Python framework that has claimed to bring engineering back to the data science world. The rationale behind using Kedro as a framework for creating maintainable and modular training code is in many aspects, similar to preferring Terraform technology over cloud-vendor native SDK for infrastructure provisioning and can be summarized in the following points:
We at GetInData|Part of Xebia are strong advocates of the Kedro framework as our technology of choice for deploying robust and user-friendly MLOps platforms on many cloud platforms. With our open-source Kedro plugins, you can write your pipeline code and focus on the target model. Then, with the Kedro plugins, you deploy it to any supported platform (see: Running Kedro… everywhere? Machine Learning Pipelines on Kubeflow, Vertex AI, Azure and Airflow - GetInData) without changing the code, making local iterations fast and moving to cloud - seamless.
As of May 2023 we support:
Google Cloud Platform (http://github.com/getindata/kedro-vertexai),
Microsoft Azure (https://github.com/getindata/kedro-azureml),
Amazon Web Services (https://github.com/getindata/kedro-sagemaker),
Airflow (https://github.com/getindata/kedro-airflow-k8s),
Kubeflow (https://github.com/getindata/kedro-kubeflow).
Now the time has come for Snowflake…
kedro-snowflake is our newest plugin that allows you to run full Kedro pipelines in Snowflake. Right now it supports:
The core idea of this plugin is to programmatically traverse a Kedro pipeline and translate its nodes into corresponding Stored Procedures and at the same time wrap them into Snowflake tasks, while preserving the inter-node dependencies to form exactly the same pipeline DAG on the Snowflake side. The end result is a Snowflake DAG of tasks like this:

that correspond to the Kedro pipeline:

It also comes with a built-in snowflights (port of the official spaceflights, extended with Snowflake-related features) starter that will help to bootstrap your Snowflake-based ML projects in seconds.
Let’s start with the snowflights Kedro starter. First, prepare your environment (i.e. your preferred Python virtual environment). First, just install our kedro-snowlake plugin:
pip install "kedro-snowflake>=0.1.2" Next, create your first ML pipeline using Kedro and Snowlake. The starter will guide you through the Snowflake connection configuration, including the Snowlake account and warehouse details:
kedro new --starter=snowflights --checkout=0.1.2Then run the starter pipeline:
kedro snowflake run --wait-for-completionThat’s it! You can see the ML pipeline execution in the Snowflake UI:

and in the terminal:
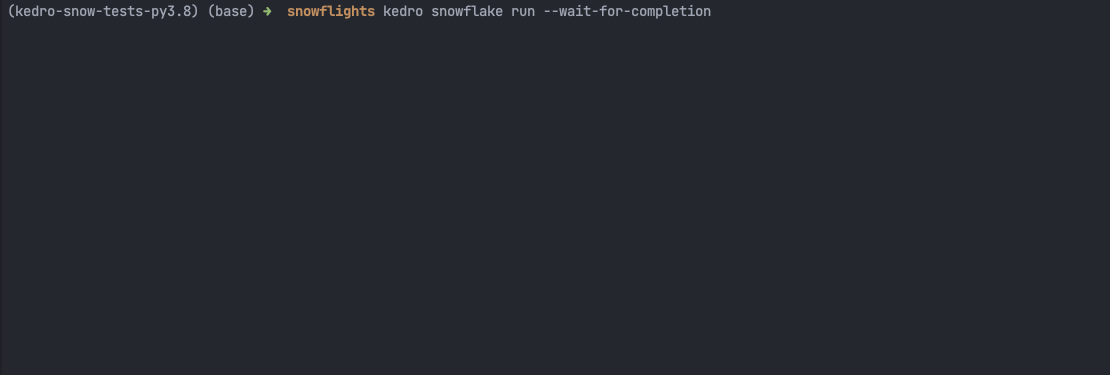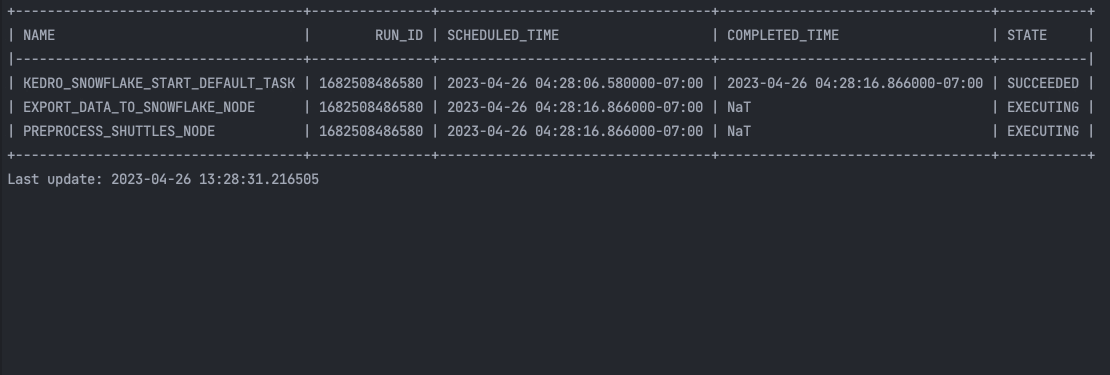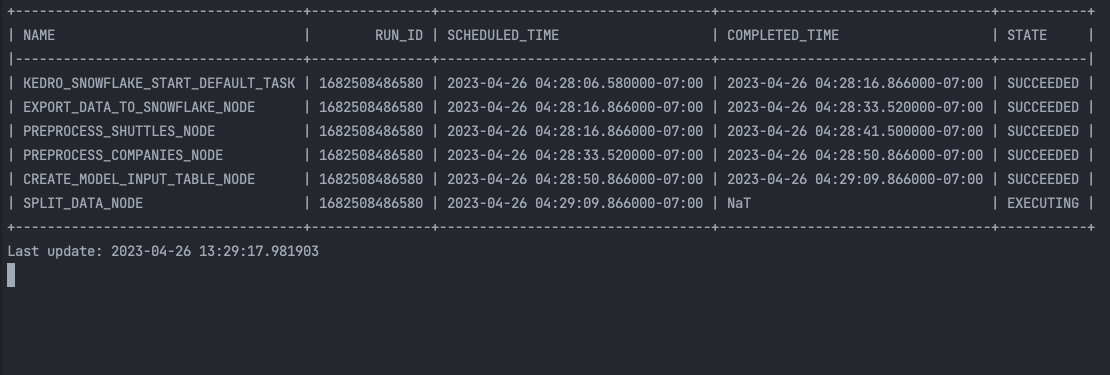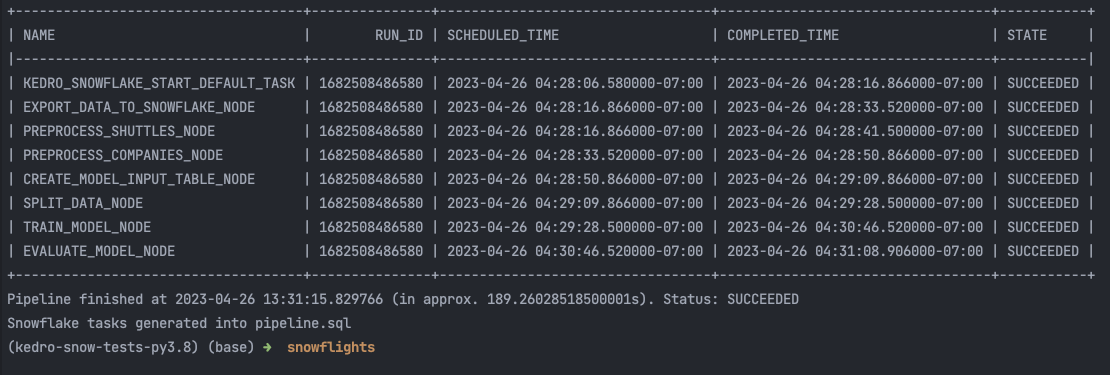
This starter will showcase the Kedro-Snowflake integration, including the connection with Snowflake, transforming an ML Pipeline in Kedro to a Snowflake compatible format, and execution of the pipeline in the Snowflake environment. Feel free to build your own pipeline based on this starter or from scratch with our plugin. See more in the following plugin documentation: Kedro Snowflake plugin documentation!
We also recommend you our video tutorial in which Marcin Zabłocki shows how to run ML pipeline on Snowflake.
In this short blog post we presented our newest kedro-snowflake plugin. Thanks to this plugin, you can build your ML pipelines in Kedro and execute them in a scalable Snowflake environment in three simple steps. Stay tuned for the second part of this blogpost in which we are going to present the whole MLOps platform and ML model deployment with the kedro-snowflake plugin being the core component of it.
WATCH KEDRO-SNOWFLAKE TUTORIAL
Interested in ML and MLOps solutions? How to improve ML processes and scale project deliverability? Watch our MLOps demo and sign up for a free consultation.
In today's digital age, data reigns supreme as the lifeblood of organizations across industries. From enabling informed decision-making to driving…
Read moreThe need for a unified format for geospatial data In recent years, a lot of geospatial frameworks have been created to process and analyze big…
Read moreQuarantaine project Staying at home is not my particular strong point. But tough times have arrived and everybody needs to change their habits and re…
Read more“Without data, you are another person with an opinion” These words from Edward Deming, a management guru, are the best definition of what means to…
Read moreThe partnership empowers both to meet the growing global demand Xebia, the company at the forefront of digital transformation, today proudly announced…
Read moreIntroduction Almost two decades ago, the first version of Spring framework was released. During this time, Spring became the bedrock on which the…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?