5 main data-related trends to be covered at Big Data Tech Warsaw 2021. Part I.
A year is definitely a long enough time to see new trends or technologies that get more traction. The Big Data landscape changes increasingly fast…
Read moreCan you build a data platform that offers scalability, reliability, ease of management and deployment that will allow multiple teams to work in parallel that also doesn’t require vendor locking? Let’s find out!
In this blog post I will present the data platform that we developed for Play. This real-world example demonstrates what can be achieved using open source technologies.
In our case we set up a cluster in an on-premises environment but the chosen technologies are fully open source and can be successfully run in any cloud provider.
Play is a consumer-focused mobile network operator in Poland with over 15 million subscribers. It provides mobile voice, messaging, data and video services for both consumers and businesses (in particular SMEs) on a contract and prepaid basis under the umbrella brand Play. Its modern and cost-ecient 2G/3G/4G LTE/5G telecommunications network covers 99% of the Polish population. Since commercial launch in 2007 Play has grown from an early challenger position to become #1 in the mobile Polish market in 2017.
In today's rapidly evolving data landscape, organizations are increasingly looking for more flexible, scalable and efficient ways to manage their data infrastructure. Hortonworks Data Platform (HDP), known for its robust big data solutions, has been a cornerstone for many enterprises in handling large-scale data processing and analytics. But as HDP life was coming to an end (end of support December 2021) PLAY needed a new solution that would address its growing needs to process and analyze data. The requirements for the new platform were as follows:
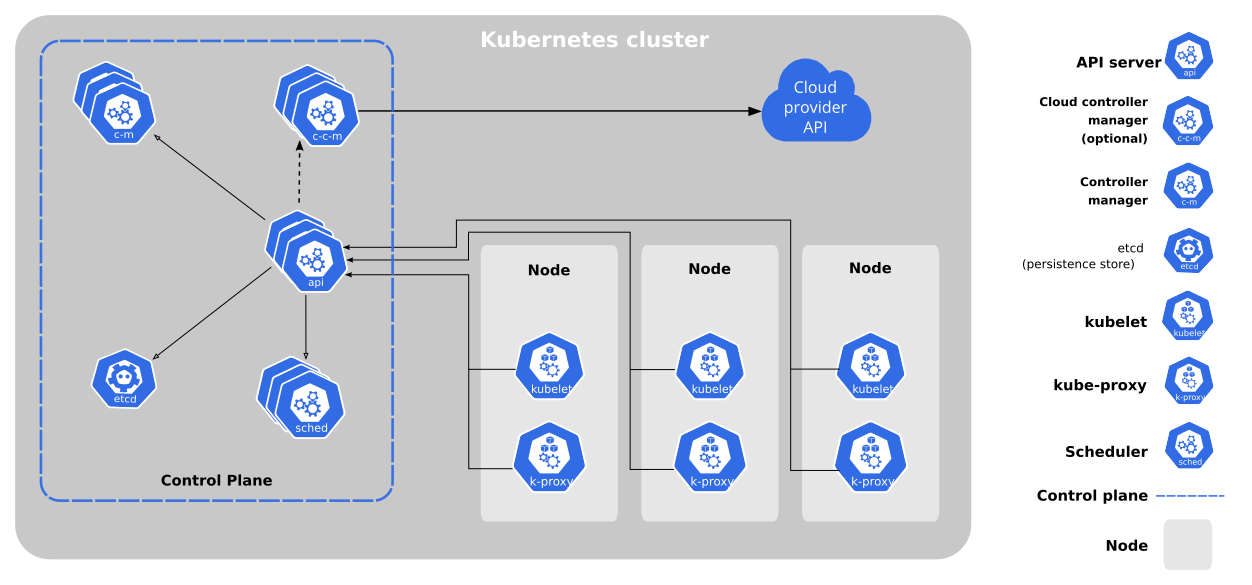
Recognizing that containerization is the best way to ship software as it provides consistency, portability and isolation, we wanted to leverage these advantages for our platform. With Kubernetes being the de facto standard for orchestrating containerized applications, we decided to utilize it as the platform for deploying applications and running big data processing workloads.
Kubernetes enables the running of applications by orchestrating containerized workloads across a cluster of machines. Applications are packaged into containers (using technologies like Docker), which bundles the application code and its dependencies. Applications are expressed as a set of declarative yaml files that define the required resources: container images, number of replicas etc. When submitted, k8s will take care of running the application, scaling if necessary and restarting it in case of failure.
Kubernetes simplified architecture
Kubernetes offers multiple features that we are looking for, some of them being:
Our existing HDP platform consisted of
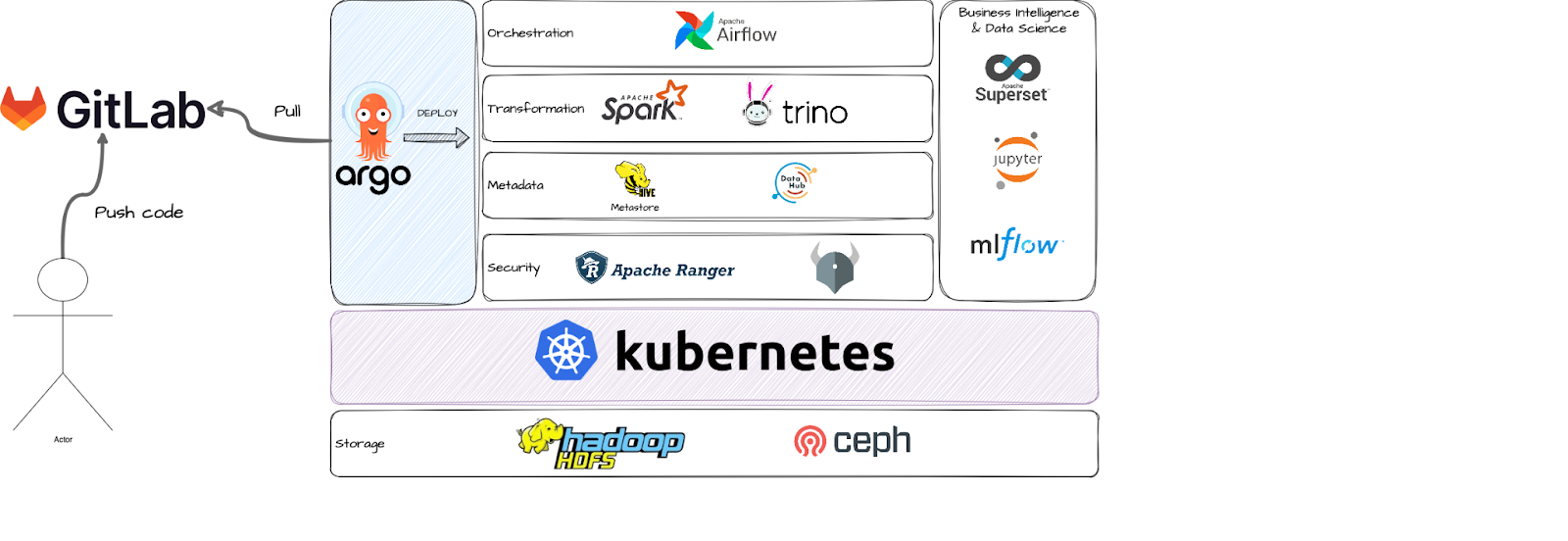
For the new cluster, we decided to use a similar set of tools, but with a significantly different deployment approach. As you can see below, all the main components, except for storage, run on Kubernetes and are managed by ArgoCD (more on that later).
Big picture of the platform
As a storage solution, we chose hadoop HDFS installed on k8s nodes separately from the k8s cluster. HDFS is a robust and scalable distributed file system designed to handle large datasets across multiple machines. Its architecture ensures high throughput, fault tolerance and efficient storage. HDFS is one of the most important components in this solution and we wanted it to be independent of Kubernetes, so that any issues related to Kubernetes wouldn’t affect HDFS. We also explored other options like Ceph and Apache Ozone, but HDFS turned out to be the best solution for us considering ease of use (as we had a lot of previous experience with it) and robustness. This setup provided us with a stable HDFS cluster with excellent performance, as the data is stored on Kubernetes nodes. To further enhance the performance, we also configured the Spark scratch directory to be located on HDFS disks. In the case of a cloud environment, HDFS could be switched to a cloud storage solution.
Apache Airflow was our scheduler of choice. It’s a powerful tool for orchestrating various workflows. This decision was straightforward, as we already had around 150 DAGs running on Airflow (waiting to be migrated) and had substantial experience with it. We deployed it on k8s using the official Airflow helmchart. By utilizing the LocalKubernetesExecutor, we ensured that resource-intensive tasks such as Spark jobs run in separate pods, while lightweight Python jobs or API interactions run as Airflow scheduler subprocesses using a minimal amount of resources.
We use Apache Spark and Trino as processing engines. Both running on k8s. Trino is a distributed SQL query engine for big data analytics. It is deployed from helmchart as a set of pods (coordinator and workers). It is used mainly by data analysts to query data in sql-like manner using various connectors - from Jupyterhub magics to local dBeaver.
We run Spark from Airflow (batch) and Jupyterhub (interactive mode). In both cases we use client mode as it gives us full control over Spark processes.
Running Spark driver as an Airflow task subprocess allows for tight integration with Airflow. Firstly, the Spark logs are streamed into Airflow task logs allowing for real time monitoring of Spark processing. Secondly, if Airflow tasks are killed (manually from UI or for any other reason) the Spark process will also be terminated. This ensures that the state of Airflow tasks accurately represents the state of Spark jobs, greatly enhancing the readability and ease of maintenance of ETL processes.
We have found running Spark on k8s very effective, even large scale - everyday. During the peak processing hour, we requested ~1500 cores and ~4TB of memory at once without any complications.
To address the data science and reporting needs, we deployed Jupyterhub and Apache Superset - everything on k8s using official helm charts.
Apache Superset is an open source alternative to paid BI solutions which allows users to build sophisticated dashboards with ease. It can work with multiple databases as a backend (in our case Trino and Postgres), provides out of the box integration with SSO and has a configurable caching layer. All of that combined with a no-code web interface and a rich set of out of the box visualizations makes Superset a appealing alternative to paid solutions.
Jupyterhub is our entrypoint for users to interact with our cluster. It enables data exploration using python notebooks. We provide users with a set of predefined connectors to Trino and Spark along with tutorials. Connectors allow querying data in multiple ways - from pure sql with sql magics through pandas to pySpark.
We also provide users with customized images that contain a set of libraries and packages of their choice. Thanks to encapsulating user environments into docker images, we ensure they have the most seamless experience possible - without worrying about venvs and dependency conflicts. The user simply chooses the desired image from the provided list and the whole environment is ready within seconds. Adding new libraries doesn't break any existing processes because the image is built with the new tag. Users can switch whenever ready and revert to the previous version if needed.


Each application with a user interface is integrated with corporate SSO using Oauth2 and access is granted based on user roles.
HDFS and Trino are secured with kerberos. For access control HDFS is integrated with Apache Ranger while Trino with Open Policy Agent(OPA). Ranger and OPA also run as applications within the Kubernetes cluster.
There was one more requirement - serving multiple teams.
In order to create the possibility of using the cluster and its processing power by multiple teams, we had to find a way to easily deploy multiple applications in a unified manner. Thankfully, there is an open source solution to that problem - and its name is ArgoCD.
The following documentation - ArgoCD is a declarative, GitOps continuous delivery tool for Kuberenetes. It means that all infrastructure is expressed as code stored in a git repository and ArgoCD is responsible for deploying that infrastructure to the k8s cluster.
I personally believe it is the most important application on our cluster, as its main job is to simplify deployments - and it does this splendidly. Keeping all infrastructure as code ensures reusability of configurations. Thanks to ArgoCD with Kustomize, a change in one configuration file is applied to all necessary namespaces. It also encourages visibility, as all pieces of infrastructure are in one place. ArgoCD also informs if any configuration on the cluster differs from the repository and what changes are going to be deployed.
So for example, if a team comes and says ‘Hey, we want to write our own Airflow pipelines,’ we simply provide them an Airflow instance. All we need to do is to set up some corporate security (git repo, user, roles and grants), create a new values-<team_name>.yaml file in git repo with team specific Airflow configurations and voila - a new Airflow instance is ready to be deployed. Then it’s just a matter of pressing the “Sync button”.
Visibility of what's deployed reduces change inertia, which in turn changes to the production environment are made more frequently because they are less scary (and they are less scary because changes are made more often ✌️). On top of that, ArgoCD provides a rollback feature in case of any problems.
When our users encountered issues with newly written Trino queries failing, we quickly identified it as a Trino bug that was fixed in a later version. Deploying the new version to production took us about an hour, including testing in two environments. This was possible because it simply involved updating the image version in the values.yaml file and then pressing “Sync” in ArgoCD.
Although the platform is now running smoothly, we encountered several challenges during the setup of its components.
At one point, when we had enough Spark processes running in parallel, the DNS service responded so slowly that the executors started to fail because they couldn't resolve the driver's name. To address this, we bypassed DNS by setting the IP address in Spark.driver.host.
We also set up our PostgreSQL databases on Kubernetes, which are used as backends for various applications. Here, we faced an issue with slow PostgreSQL responses. It took some time to realize that the problem was due to a slow filesystem. We use Ceph for persistent storage in Kubernetes, and slow HDD drives caused the issue. The problem was resolved when we changed the PVC storage class to one with SSD drives on Ceph.
Applying containerization and best software practices, such as version control, infrastructure as code and automated, regular deployments allowed us to build a data platform that efficiently processes large amounts of data, serving multiple teams and various user needs. The above principles ensure that the platform is maintainable, doing upgrades, fixes and adding new components straightforwardly.
We also created a set of predefined configs and interfaces that provide access to data, allowing users to focus on generating business value.
Last but not least - all of this was achieved using open-source technologies 💪.
Watch the presentation we gave during the Big Data Technology Summit 2024 about this project: WATCH VIDEO.
If you want to check if this kind of data platform is implementable for your business, just sign for a free 35 minute consultation with one of our experts.
A year is definitely a long enough time to see new trends or technologies that get more traction. The Big Data landscape changes increasingly fast…
Read moreBeing a Data Engineer is not only about moving the data but also about extracting value from it. Read an article on how we implemented anomalies…
Read moreHardly anyone needs convincing that the more a data-driven company you are, the better. We all have examples of great tech companies in mind. The…
Read moreLet’s take a little step back to 2023 to summarize and celebrate our achievements. Last year was focused on knowledge-sharing actions and joining…
Read moreIntroduction Many teams may face the question, "Should we use Flink or Kafka Streams when starting a new project with real-time streaming requirements…
Read moreBig Data Technology Warsaw Summit 2021 is fast approaching. Please save the date - February 25th, 2021. This time the conference will be organized as…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?