In this blogpost series, we share takeaways from selected topics presented during the Big Data Tech Warsaw Summit ‘24. In the first part, which you can read here, we shared insights from the Spotify, Dropbox, Ververica, Hellofresh and Agile Lab case studies. This time we will focus on the Allegro and Play case studies, but also on: migration from Spark on Hadoop to Databricks, the Agile Data Ecosystem and how to build your personal RAG-backed Data Copilot.
But before we dive into it, we want to invite you to the next network opportunity: InfoShare - the biggest Western Union opportunity where our colleague Marek Wiewiórka will perform on the DataMass Stage about your personal RAG-backed Data Copilot. As a partner, we have a discount code for you: ISC24-GetInData10 for a 10% discount if you register here. So, let’s meet on 22-23 May in Gdańsk, and now let’s jump to the meat from Big Data Tech ‘24!
3D: Data Quality, Data Ecosystem and Big Data Transformation
Piotr Menclewicz, Staff Analytics Engineer at GetInData
Your personal LLM and RAG-backed Data Copilot; Marek Wiewiórka
Personalized AI copilot to enhance the productivity of your data team
The concept of coding copilots has been around for a while. In recent years, they have been proven to boost the productivity of developers. But there is even more potential to revolutionize how your data teams operate. In a recent talk, Marek Wiewiórka, Chief Data Architect at GetInData, explained how using a copilot tailored to your organization can be a real game-changer. There are three strong arguments that support this statement.
Not Just a Tool, But a Team Member
One of the key advantages of a personalized data copilot is its ability to integrate seamlessly into the specific data environment of a company. Unlike generic copilots, a tailored solution leverages the company’s specific data, including data models, user queries and other meta information. This contextual awareness transforms the copilot from a simple tool to an integral team member who understands the nuances of your data landscape.
Specialized and Secure: The Trend Towards Nimble Models
The shift towards smaller, specialized AI models is reshaping the landscape. These models are not only getting better in terms of the performance but can also be run locally. This enhances security as the sensitive data is only processed in-house. As technology progresses, these models are likely to become standardized, providing organizations with custom solutions that large, generalized models cannot match.
Consistency and Security in Data Practices
Organizations can embed their best practices directly into the copilot. This promotes a uniform approach to data management across the entire organization. Additionally, it ensures that the copilot adheres to and reinforces the organization's standards, making it a reliable component of the data management ecosystem.
When using your custom solution, you don’t need to compromise the user experience. The personalized data copilot integrates smoothly with popular coding environments such as Visual Studio Code. This integration provides a familiar interface for users, who can instruct the copilot in a natural language to carry out repeatable, yet complex tasks such as locating data sources, writing queries, creating dbt models and generating tests.
The technical backbone of the personalized copilot is based on Retrieval-Augmented Generation (RAG) architecture. This architecture capitalizes on a company's specific data context, supporting both commercial and open-source models. Despite the rapid advancements in the open-source domain, GPT-4 remains the most capable model based on the Bird-SQL benchmark, although non-commercial models are catching up.
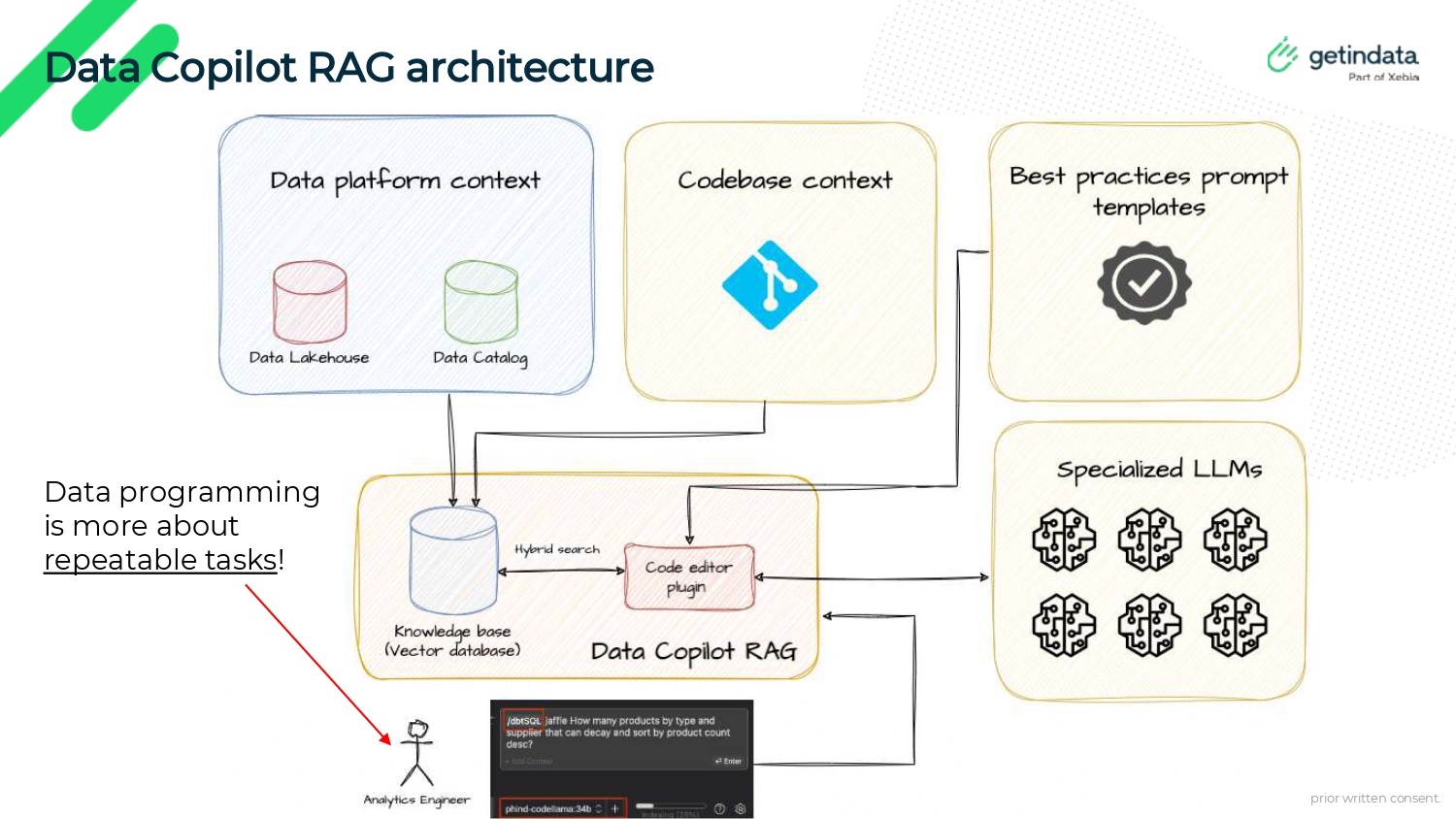
Looking ahead, the potential enhancements for the copilot are promising. By utilizing the knowledge from the history of user queries, improvements like few-shot prompting can further personalize the experience. Fine-tuning can also improve compatibility with data-specific frameworks, like dbt. It can even support specific use cases, like platform-to-platform migrations, which presents a significant opportunity for companies aiming to modernize their data stacks.
If you found this interesting, Marek Wiewiórka will also present during InfoShare (May 22nd). Register here to not to miss out.
Transforming Big Data: Migration from Spark on Hadoop to Databricks; Krzysztof Bokiej
From On-Prem to On-Point: How Databricks is Revolutionizing Data Management
Is your organization still tethered to on-prem Hadoop for handling big data? During his session, Krzysztof Bokiej delved into why moving to a cloud platform like Databricks isn’t just a shift in technology - it's a smart business decision.
Here’s why switching makes sense:
Cost Efficiency: On-prem solutions require hefty upfront investments and constant maintenance costs - expenses that cloud platforms like Databricks incur can drastically change with their pay-as-you-go models.
Flexibility: Databricks offers scalable solutions that adjust to your needs, not the other way around. This means you only pay for what you use, avoiding the pitfalls of underutilized or overstretched resources.
Advanced Tools: Access state-of-the-art collaborative tools out of the box, enhancing your team's productivity and capabilities.
Migration Challenges & Tips:
Plan Carefully: Migration is complex. Krzysztof emphasized the importance of a well-structured plan and shared the potential pitfalls to avoid, such as modifying pipelines during the transition. Instead, document any issues and address them post-migration to keep things streamlined.
Hybrid Options: Not ready to fully commit to the cloud? Krzysztof suggests a hybrid approach, deploying Databricks on a Kubernetes cluster. This strategy allows you to leverage all of the cloud benefits, whilst maintaining control over some infrastructure elements.
The Agile Data Ecosystem from First Principles; Jonathan Sunderland
"The greatest enemy of knowledge is not ignorance; it is the illusion of knowledge." — Stephen Hawking
In his energetic and thought-provoking talk, Jonathan Sunderland, a seasoned expert with over 30 years of experience, highlighted how development teams could dramatically increase their value by embracing first principles thinking.
He distilled his extensive experience into a fundamental insight: the dual levers of boosting company value - revenue enhancement and cost reduction. This might sound straightforward, but the challenge lies in executing it effectively. The costs of initiatives are often apparent upfront, whereas their value materializes only in hindsight.
To bridge this gap, Jonathan offered several actionable tips. One practical approach that resonated with me, which I've seen whilst transforming data initiatives in action, is establishing robust feedback loops. It's especially important for data teams to shift their focus from merely generating insights to acting on them decisively and measuring the outcomes before advancing to the next improvement cycle.
Jonathan also highlighted the critical role of data quality in shaping effective business strategies. He stressed that high-quality data is the backbone of any successful feedback loop, as it ensures that the insights derived are accurate and actionable. Poor data quality can lead to misguided decisions and missed opportunities. Therefore, investing in robust data management and validation processes is essential for organizations looking to capitalize on their strategic initiatives and drive meaningful change.
Achieving High-Quality Data Products: our journey at Allegro; Wojciech Taisner
Navigating Data Quality Challenges at Scale: Lessons from Allegro
As a leader in Central European e-commerce, Allegro needs no introduction. The company handles petabytes of data. Have you ever wondered how it takes care of data quality?
Allegro isn't just any e-commerce company, it processes enormous volumes of data daily. The primary challenge at this scale is not just collecting data but ensuring its quality and usability across different departments and for various applications, from data pipelines to AI solutions.
In his presentation, Wojciech Taisner shared valuable insights on the systematic approach needed to manage data quality in a complex environment. The main problem, if you don't use proper tools, is that data errors are detected late in the process, often during the business analysis phase, which is far from ideal. This can lead to poor decisions or cause stakeholders to lose trust in the data, potentially delaying the adoption of best data-driven practices.
Allegro's response was to create a bespoke solution that integrated Airflow with predefined templates and involved humans in the loop. This approach helped standardize data handling processes across teams, ensuring consistency and quality.
The solution is easy to adopt and flexible. However, it faces challenges, particularly with scalability as the system grows. Human involvement, while valuable, limits the speed of adoption. To overcome this, Allegro is experimenting with different approaches, including Gen AI.
Reflecting on Wojciech’s presentation, what stood out to me was the process of finding a balance between human expertise and automated systems. It’s a powerful reminder that while AI and automation are transformative, human involvement remains significant in different stages of the process.
Migrating from Hadoop to Kubernetes - A Play Case Study by GetInData at Big Data Tech Warsaw
Michał Kardach, Staff Data Engineer at GetInData
An important presentation titled "Kubernetes Takes the Wheel" was delivered by Kosma Grochowski, Tomasz Sujkowski, and Radosław Szmit from GetInData. Each presenter brought significant expertise to the discussion: Tomasz Sujkowski, with over two decades of experience in IT and specializing in big data; Radosław Szmit, an experienced data platform architect; and Kosma Grochowski, a skilled data engineer. This session focused on Play, a Polish telecom company, and its journey from a traditional Hadoop ecosystem to a modern, Kubernetes-based architecture.
Legacy System
The team began by summarizing the legacy system at Play. Initially, the company utilized a Hadoop cluster managed by Hortonworks, a popular choice a decade ago which is now part of Cloudera. This system incorporated familiar tools such as Apache Presto (now Trino), Spark for processing and Airflow for orchestration. However, the rapid evolution of technology highlighted the need for a more flexible and scalable environment.
Transition to Kubernetes
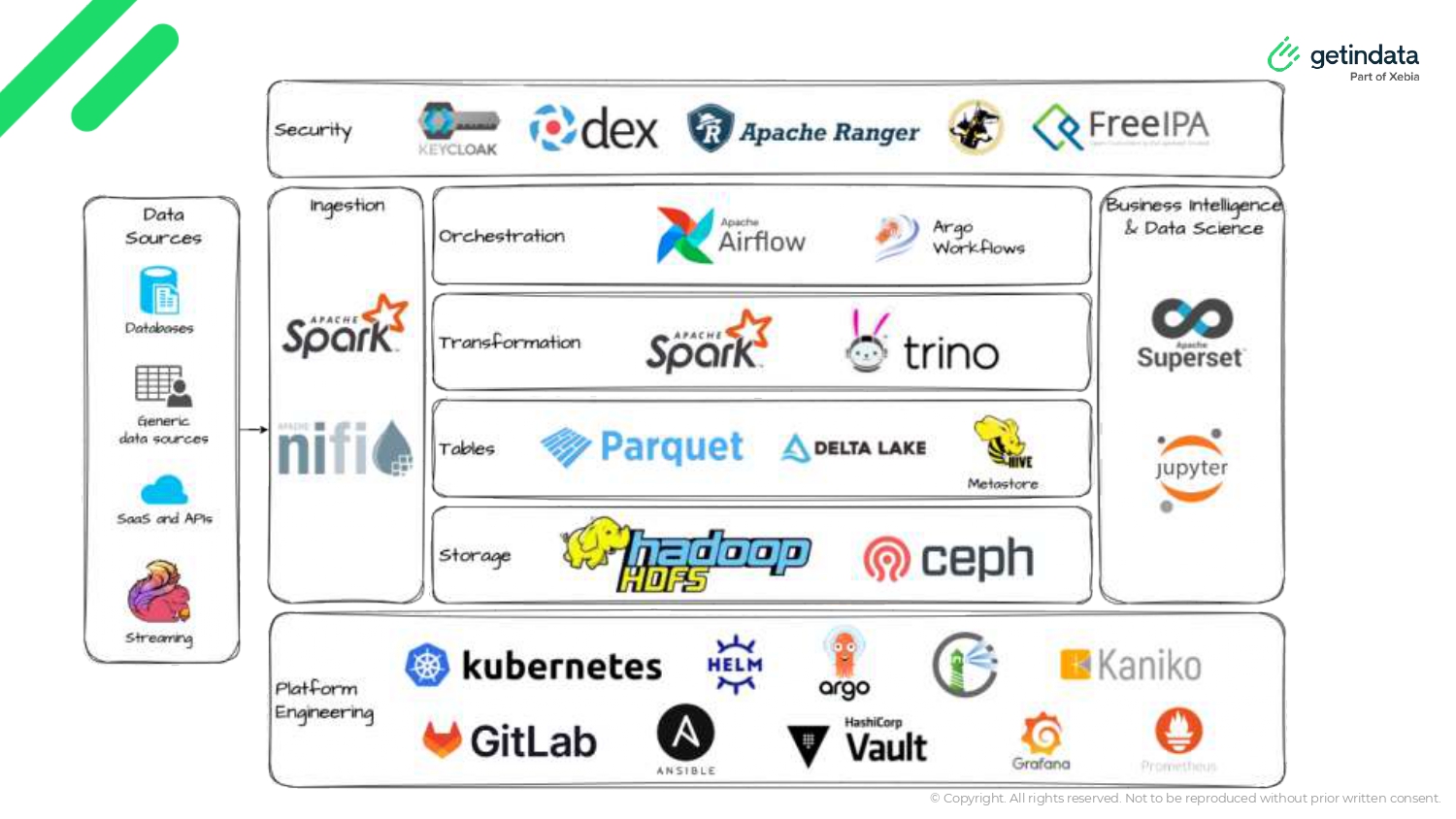
The core of the presentation detailed the transition to Kubernetes, seeking to improve scalability, maintainability and cloud-native capabilities. Interestingly, essential tools such as Spark and Airflow were retained, emphasizing their continued relevance and adaptability in today’s world. The shift was not just about changing tools but transforming the underlying infrastructure to a containerized, microservices approach, which introduced significant improvements in system deployment and management.
The updated stack includes:
- Data Handling: Apache NiFi for ingestion and Trino for transformation.
- Orchestration and Monitoring: Continued use of Apache Airflow, supplemented by Grafana for monitoring and HashiCorp Vault for security.
- Storage and Security: Integration of HDFS for storage, Apache Ranger for security and the introduction of ArgoCD for GitOps continuous delivery. The new system emphasizes enhanced security measures such as Kerberos and SSO integration, meeting the company’s requirements.
Challenges and Solutions
The speakers also shared some of the challenges encountered during the migration. A significant limitation was the problematic integration between Ozone and Spark, which ultimately led to retaining HDFS separately from Kubernetes. Also, the proof of concept (PoC) stage was crucial in validating functional requirements and addressing issues related to security and networking.
Conclusion
GetInData's case study on Play's migration to Kubernetes provided a compelling narrative about the evolution from monolithic architectures to flexible, scalable environments. The presentation not only demonstrated how strong and reliable the new system is, but also served as an inspiration for companies facing similar technological transitions. This transition showed how Play's adaptation of Kubernetes enabled a more efficient deployment process and better resource management, setting a new standard for data platforms in the telecom sector.
If you missed the Big Data Tech Summit, our reviewer has done their best to provide you with the most valuable pieces of it. See you in Gdańsk in May and next year in Warsaw. For more insights from the conference, follow the conference profile on LinkedIn.