
Use-cases/Project
Enabling Hive on Spark on CDH 5.14 — a few problems (and solutions)
Recently I’ve had an opportunity to configure CDH 5.14 Hadoop cluster of one of GetInData’s customers to make it possible to use Hive on Spark…
Read morePlease dive in the second part of a blog series based on a project delivered for one of our clients. If you miss the first part, please check it here.
In several of the CI/CD jobs in our project, we create container images and upload them to GitLab's Registry. Building container images in GitLab's CI/CD requires infrastructure preparation, or we have to use a tool other than Docker. If we want to build images using Docker, then we must give the Docker client access to the Docker daemon socket, which is not recommended for security reasons. If we want to use shared GitLab.com runners, access to the daemon socket is not possible.
We can solve the problem in several ways:
buildah tool to build the container image inside the container and the skopeo program to upload the image to the GitLab Registry. Both programs are part of the https://github.com/containers project and do not require a privileged daemon norrootaccess (unlike Docker).kaniko. Kaniko is a tool dedicated to building container images in Kubernetes and in containers. Like buildah, it doesn't require special permissions. An example of its use is described in the official GitLab documentation.Our team has already had experience with Kaniko in other projects, so we made use of it in this project.
The definition of a job using kaniko in the .gitlab-ci.yml looks like this:
build-base-image:
stage: prepare
image:
name: gcr.io/kaniko-project/executor:debug
entrypoint: [""]
script:
- echo
"{\"auths\":{\"$CI_REGISTRY\":{\"username\":\"$CI_REGISTRY_USER\",\"password\":\"$CI_REGISTRY_PASSWORD\"}}}" > /kaniko/.docker/config.json
- /kaniko/executor --context $CI_PROJECT_DIR --dockerfile
$CI_PROJECT_DIR/Dockerfile --destination
$CI_REGISTRY_IMAGE:$CI_COMMIT_TAGAs you can guess, after studying the above code fragment, Kaniko builds a container image and immediately uploads it to the indicated image registry.
GitLab has an integrated container image registry (Registry). A one-time password is created for each job, which allows you to use Registry without having to manually create a dedicated account. GitLab passes the login and temporary password to the Runner, which then sets them in the environment variables of the job process.
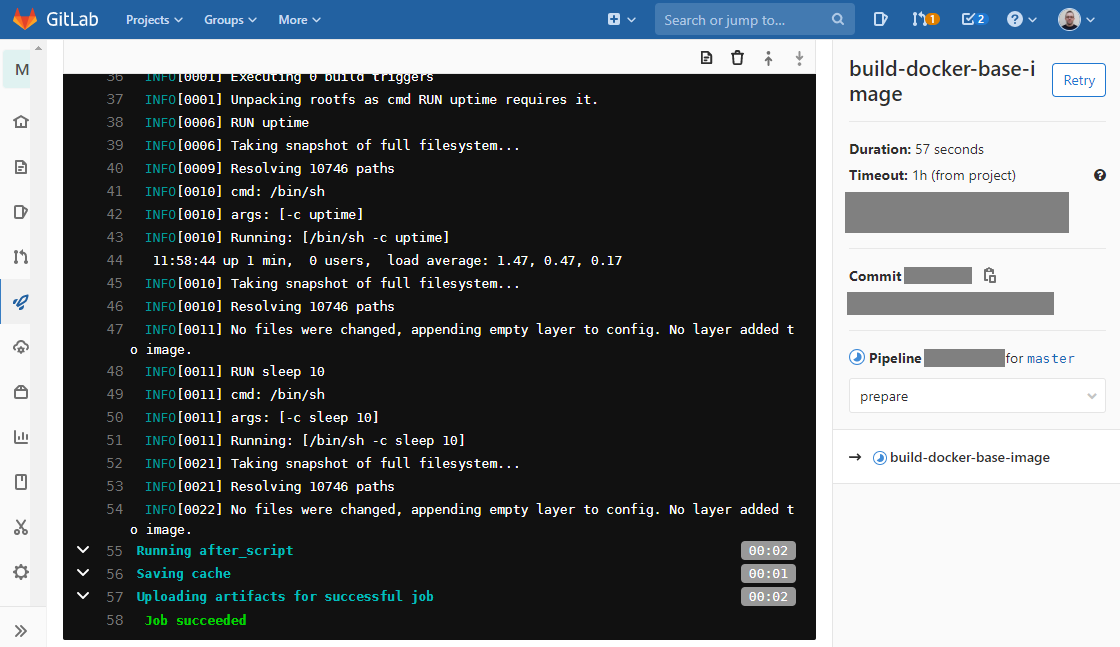
This is the end result of a successful job output that creates a container image using Kaniko and uploads it to the Registry built into GitLab:
In our project, some jobs take a very long time, longer than the lifetime of a one-time Registry password. Limiting the duration of such a one-time password is necessary from the security point of view.
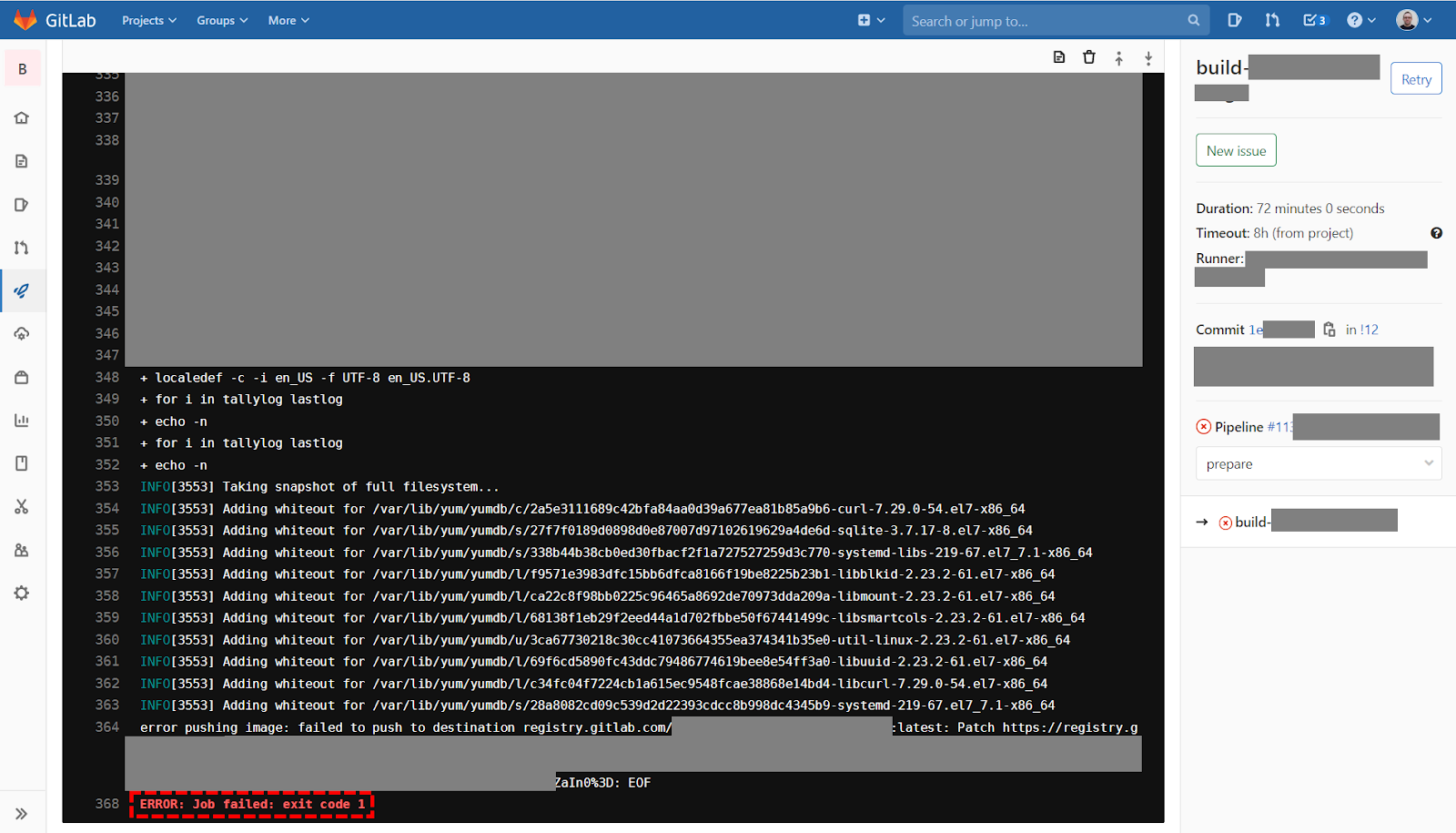
Uploading the image to the Registry fails and ends with the following error:
We solved this problem in a traditional way:
After these modifications, we no longer had problems uploading container images to the Registry, even if the CI/CD job took 3 hours.
If you use paid GitLab-as-a-service plans, you can use a certain number of minutes for the CI pipeline, i.e. shared Runners. Each of the paid plans has a different limit. Using shared Runners is very convenient because we don't have to worry about maintaining our own Runners and thus save time and money. The limit may be sufficient in some projects, but in our project we quickly reached the monthly limit.
You will see this type of message when you use the available time of shared Runners in a given month:
We solved this problem by setting up a dedicated Kubernetes cluster for Runners. We allow GitLab to decide which Runner to use (shared or our own). Thanks to this, the load is distributed to both types of Runners, we reduce expenses and shorten the time of pipeline execution.
Instructions for using Kubernetes cluster as the platform for Runners are described in the Problem 2 section.
If the runner or container we use in our CI/CD has locales that do not support UTF-8, and the user making commits to the repository that has characters that are not ASCII in the name or surname, then the CI/CD job may end with the following error:
FAILURE: Build failed with an exception.
* What went wrong:
Could not set the value of environment variable 'GITLAB_USER_NAME':
could not convert string to current localeThere is even an issue with this in this GitLab project.
A workaround is also provided there. You can change the value of the GITLAB_USER_NAME variable so that it doesn't contain non-ASCII characters. It can be assigned, for example, to the value of the variable containing the user's login (assuming that the login consists only of ASCII characters).
To the before_script section in .gitlab-ci.yml, add:
# Workaround for "Could not set the value of environment variable
'GITLAB_USER_NAME': could not convert string to current locale" problem.
# https://gitlab.com/gitlab-org/gitlab-foss/issues/38698
- export GITLAB_USER_NAME=$(echo $GITLAB_USER_LOGIN)Follow our profile on Linkedin and stay up to date for the next part!
Recently I’ve had an opportunity to configure CDH 5.14 Hadoop cluster of one of GetInData’s customers to make it possible to use Hive on Spark…
Read moreThe 2024 edition of InfoShare was a landmark two-day conference for IT professionals, attracting data and platform engineers, software developers…
Read moreThe adage "Data is king" holds in data engineering more than ever. Data engineers are tasked with building robust systems that process vast amounts of…
Read moreAt GetInData we use the Kedro framework as the core building block of our MLOps solutions as it structures ML projects well, providing great…
Read moreNowadays, we can see that AI/ML is visible everywhere, including advertising, healthcare, education, finance, automotive, public transport…
Read moreFlink complex event processing (CEP).... ....provides an amazing API for matching patterns within streams. It was introduced in 2016 with an…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?